深層学習運動エネルギー汎関数AdvanceSoft25の計算速度ベンチマーク#
材料物性予測のための密度汎関数理論(DFT)計算の解法として最も広く知られているKohn-Sham DFT (KS-DFT)は、電子の軌道を用いる必要があるため、計算コストが系のサイズに対しておおよそで増大するという課題を抱えています。この課題を解決する計算手法として提案されたOrbital-Free DFT (OF-DFT)は、軌道を使わずに電子密度を直接最適化することで計算コストがでスケールし、大きなサイズの系に対しての高速な計算を可能にしました。
一方で、従来のOF-DFTでは、実用に耐えうる精度の運動エネルギー汎関数が未知であることが課題でした。そこでアドバンスソフト株式会社では、独自の場の深層化アルゴリズムを適用した深層学習運動エネルギー汎関数 AdvanceSoft25 (AS25)を開発し、Advance/OF-DFTに搭載しました。 AS25は、OF-DFTの最大のメリットであるの計算コストを維持しながら、従来の運動エネルギー汎関数よりも高精度な電子密度計算を実現しました(計算精度の詳細についてはこちらの記事を参照してください)。
本事例では、深層学習運動エネルギー汎関数AdvanceSoft25の計算速度のベンチマークを実施しました。
計算条件#
計算対象とする構造として、Materials Projectより取得したfccのAlの構造ファイル (mp-134) をもとに、等方的にスケーリングを変えながらスーパーセルモデルを作成しました。
以下の条件で各スーパーセルに対してKS-DFT及びOF-DFTを実行し、計算時間を計測しました。
KS-DFTの計算条件
- 波動関数のカットオフエネルギー : 540 eV
- エネルギーの収束閾値 : ~ 1×10-7 eV
- 固有値ソルバー : Davidson
- k点サンプリング : 0.05 Å-1
OF-DFTの計算条件
- 波動関数のカットオフエネルギー : 540 eV
- エネルギーの収束閾値 : ~ 3×10-3 eV/atom
- 最適化アルゴリズム : CG-HS
- プレコンディショナー : damping関数 (カットオフ半径 = 0.265 Å) 1
KS-DFTにはQuantum ESPRESSO 6.7 (アドバンスソフト改修版)を使用しました。また、OF-DFTの運動エネルギー汎関数(KE汎関数)としては、AS25に加えて、既存のよく知られているTFλvW、LKT、HCを用いて計算を行いました。
また、本事例で使用した計算機のスペックを以下に示します。
- CPU : Intel Xeon Gold 6330 @ 2.00GHz
- 使用CPU数 : 24 (12コア × 2 CPU)
- 使用メモリ : 128 GB (8GB DDR4-3200 RDIMM × 16)
KS-DFT及びAS25以外のOF-DFTにおいては、MPI並列(24プロセス)、AS25においてはOpenMP並列(24スレッド)を用いて計算を実行しました2。
計算結果#
以下の表及びグラフに、各スーパーセルの原子数と計算手法ごとの計算時間を示します。 表におけるカッコ内の値及びグラフ内の点線はフィッティング3による予測値です。 なお、本事例では、計算時間の都合上、500原子以上の構造に対するKS-DFTを実施していません。また、AS25、TFλvW、LKT、HCはそれぞれ2048原子、6912原子、6912原子、5324原子の時点でメモリ不足となり計算が停止しました。
| 原子数 | KS (sec) | AS25 (sec) | TFλvW (sec) | LKT (sec) | HC (sec) |
|---|---|---|---|---|---|
| 4 | 0.77 | 1.59 | 0.08 | 0.09 | 0.66 |
| 32 | 16.93 | 7.73 | 0.15 | 0.20 | 2.01 |
| 108 | 229.98 | 20.40 | 0.45 | 0.73 | 6.21 |
| 256 | 2283.35 | 40.72 | 0.99 | 1.59 | 12.71 |
| 500 | (1.7×104) | 91.99 | 2.00 | 3.40 | 25.99 |
| 864 | (8.8×104) | 160.79 | 3.31 | 6.00 | 43.61 |
| 1372 | (3.5×105) | 222.00 | 4.57 | 8.80 | 61.73 |
| 2048 | (1.2×106) | (347.96) | 8.13 | 14.06 | 100.43 |
| 2916 | (3.4×106) | (495.43) | 12.22 | 21.52 | 156.88 |
| 4000 | (8.7×106) | (679.60) | 20.59 | 29.50 | 212.08 |
| 5324 | (2.1×107) | (904.55) | 28.79 | 42.89 | (277.91) |
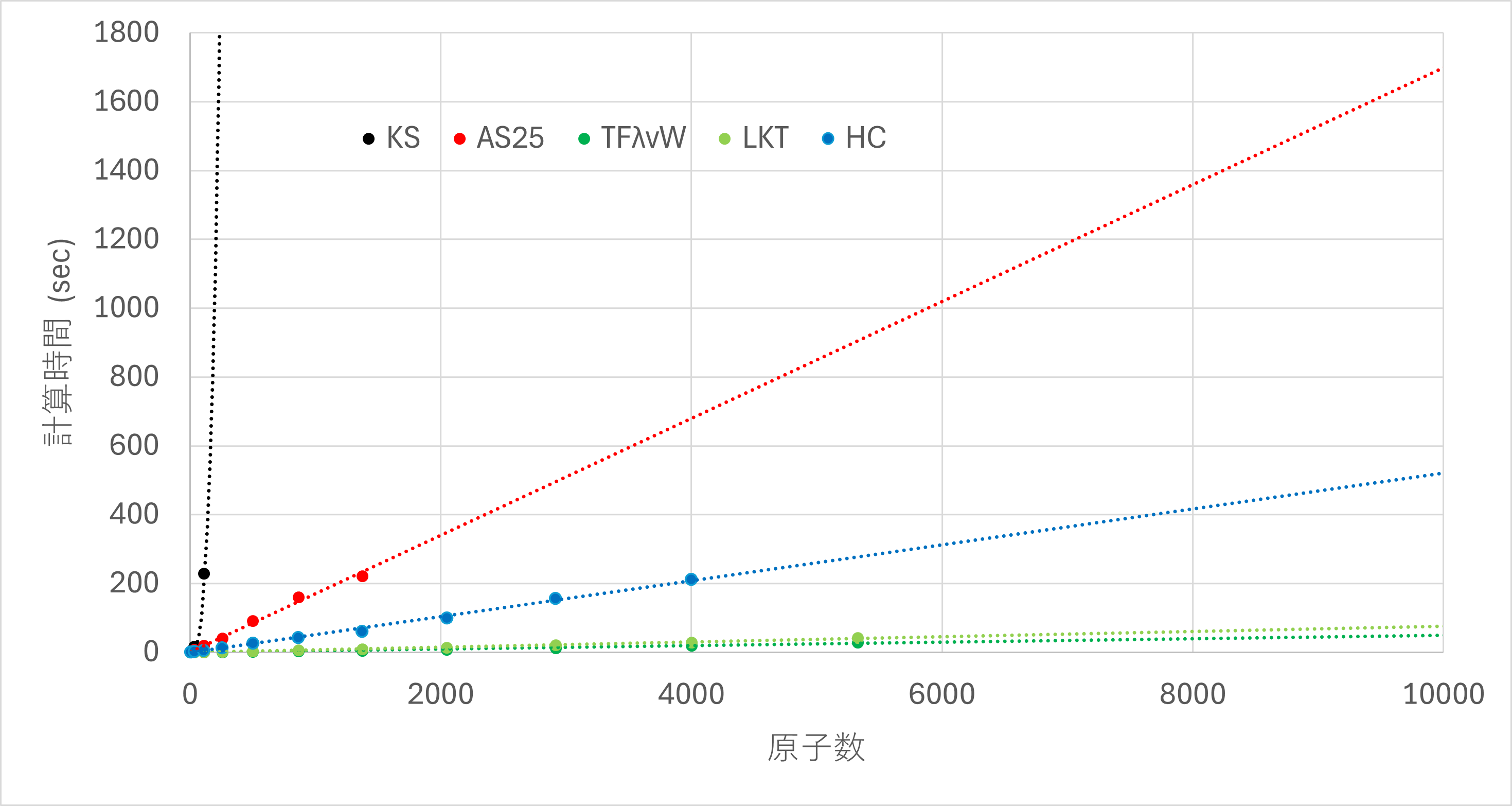
上記の結果からは、KS-DFTでは原子数を増加させると、計算時間が爆発的に増大していることがわかります。KS-DFTでは、864原子で計算時間は8.8×104 sec ~ 1 dayに達し、5324原子で計算時間は2.1×107 sec ~ 244 dayとなり、実質的に計算不可能となることが予測されます。
一方で、AS25では、原子数に対して計算時間は線形に増大し、KS-DFTに比べて圧倒的に高速であることがわかります。864原子で計算時間は160.79 secであり、5324原子においても計算は900 sec程度で完了することが予測されます。
並列化手法としてスレッド並列にのみ対応しているAS25は、MPI並列に対応している従来KE汎関数に比べるとやや遅いものの、計算精度の面で従来KE汎関数より優れていることを考慮すると、数千原子以上の大きな系に適用する場合に実用上最も優れているのはAS25だと考えることができます。
また、AS25はGPUを使用しての計算に対応している為、GPUマシンではより高速な計算が可能となります。
総括と展望#
本事例の結果から、弊社が独自開発した深層学習運動エネルギー汎関数AdvanceSoft25を用いたOF-DFT計算では、1000原子以上の大きな系に対しても、KS-DFTに比べて圧倒的に高速に電子密度計算を実行できることがわかりました。
KS-DFTでは、計算時間がで増大するため、数千~数万原子以上のサイズの系を現実的な時間内に計算することは非常に困難です。 一方、AS25を用いたOF-DFTでは、よりメモリサイズの大きいマシンを使用するだけで、1万原子以上の大きな系についても数時間程度での高速な計算が可能になると考えられます。
また、今後はAS25のMPI並列対応も予定しており、さらなる高速化が期待できます。