[Advance/NeuralMD Pro] 8基のNVIDIA H100搭載マシンにおけるベンチマーク#
Neural Network力場を用いた、LAMMPSによる分子動力学計算のベンチマークを8GPU (NVIDIA H100) 搭載マシン上で実施しました。 本事例では、以前の32GPU (NVIDIA A100) 搭載クラウドにおけるベンチマークで用いた硫化物リチウムイオン伝導体Li10GeP2S12の21,600原子系および98,000原子系スーパーセルモデルについてベンチマーク計算を実施し、A100を用いた場合およびCPUのみを用いた場合との比較も行いました。
計算機環境およびMD計算条件#
本事例で使用した計算機のスペックを以下に示します。
- CPU:AMD EPYC 9554 (64 cores) × 2
- GPU:NVIDIA H100 × 8
- コンパイラ:GCC
- MPIライブラリ:OpenMPI
- 行列演算ライブラリ:OpenBLAS
- CUDA:12.2
計算機環境の用意・使用にあたっては、HPCシステムズ様にご協力いただきました。
分子動力学計算は100ステップ行い、時間刻み幅は0.5 fsとしました。また、同様の分子動力学計算を1 ns間実施するのに要する日数を計算結果から算出しました。
CUDAスレッド数およびMPIプロセス数の最適化#
本ベンチマークでは初めに、NVIDIA A100を用いた32GPU搭載クラウドにおけるベンチマークと同様にして、CUDAスレッド数を256とし、1つのGPUにつき4つのMPIプロセスを起動して計算を行いました。この計算条件においては、並列化効率および計算速度が想定を下回ったため、CUDAスレッド数およびMPIプロセス数の最適化を試みました。 最適化後のCUDAスレッド数は128、MPIプロセス数は1GPU当たり16となりました。
下表に最適化前後での計算条件および計算時間を示します。表の各セルの上段が最適化後、下段の丸括弧内が最適化前に対応します。下表からわかるように、98,000原子系では最適化によって計算速度が大きく向上しています。一方で、21,600原子系ではGPU × 4およびGPU × 8の条件において計算速度がむしろ遅くなっていますが、原因としては系のサイズに対してMPIプロセス数が過多であることが考えられます。
| GPU × 1 | GPU × 2 | GPU × 4 | GPU × 8 | |
|---|---|---|---|---|
| CUDA スレッド数 |
128 (256) |
128 (256) |
128 (256) |
128 (256) |
| MPI プロセス数 |
16 (4) |
32 (8) |
64 (16) |
128 (32) |
| 計算時間 (sec) (21,600原子) |
6.98 (9.20) |
4.09 (4.85) |
2.82 (2.77) |
2.18 (1.47) |
| 計算時間 (sec) (98,000原子) |
29.45 (41.52) |
14.65 (21.84) |
7.85 (12.53) |
4.57 (6.37) |
| day/ns (21,600原子) |
1.62 (2.13) |
0.95 (1.12) |
0.65 (0.64) |
0.50 (0.34) |
| day/ns (98,000原子) |
6.82 (9.61) |
3.39 (5.06) |
1.82 (2.90) |
1.06 (1.47) |
H100とA100の比較#
H100のベンチマーク結果とA100のベンチマーク結果との比較を下表に示します。表の各セルの上段がH100、下段の丸括弧内がA100を用いた場合の結果に対応します。表中のH100の結果は、CUDAスレッド数およびMPIプロセス数を最適化した後のものです。
21,600原子系では、GPU × 1およびGPU × 2の場合に、H100がA100のおよそ2倍程度の計算速度を実現していますが、GPU × 8になると両者の計算速度の差はほとんどなくなります。 このことから、計算対象となる系のサイズが小さい場合には十分な高速化は期待できないと考えられます。 一方で、98,000原子系では、H100は常にA100の2.2~2.4倍ほど高速であることがわかります。
| GPU × 1 | GPU × 2 | GPU × 4 | GPU × 8 | |
|---|---|---|---|---|
| CUDA スレッド数 |
128 (256) |
128 (256) |
128 (256) |
128 (256) |
| MPI プロセス数 |
16 (4) |
32 (8) |
64 (16) |
128 (32) |
| 計算時間 (sec) (21,600原子) |
6.98 (15.35) |
4.09 (7.84) |
2.82 (4.16) |
2.18 (2.29) |
| 計算時間 (sec) (98,000原子) |
29.45 (69.12) |
14.65 (35.64) |
7.85 (18.08) |
4.57 (9.84) |
| day/ns (21,600原子) |
1.62 (3.55) |
0.95 (1.82) |
0.65 (0.96) |
0.50 (0.53) |
| day/ns (98,000原子) |
6.82 (16.00) |
3.39 (8.25) |
1.82 (4.19) |
1.06 (2.28) |
CPUとの比較#
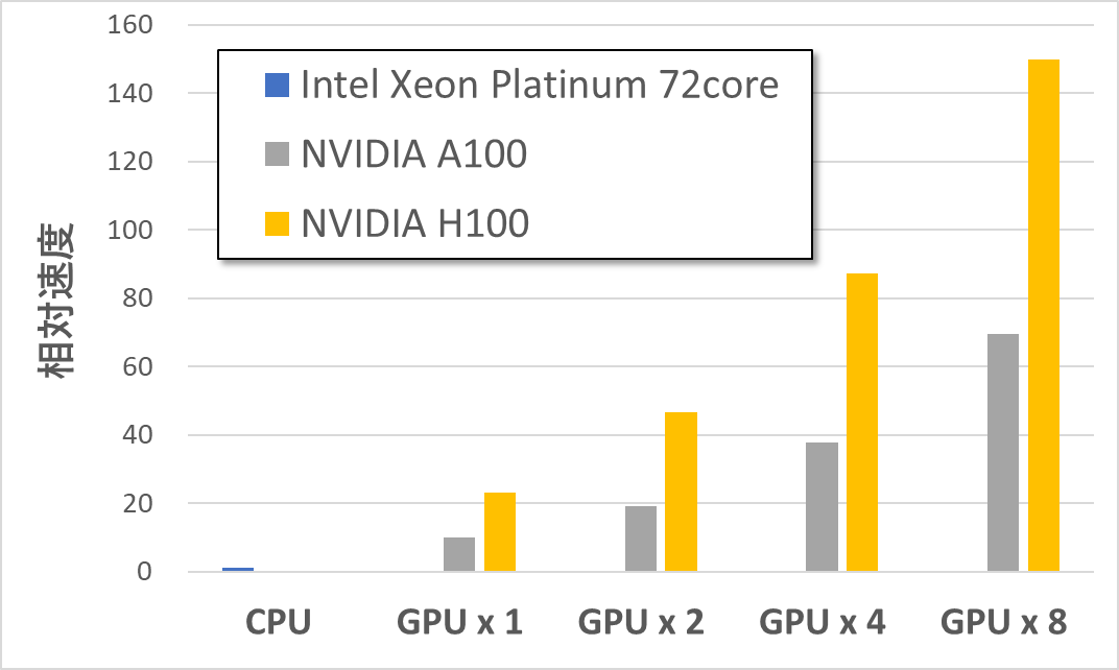
AWSにおいてCPU (Intel Xeon Platinum / 72core) を1つ用いた場合の計算速度を1として、H100およびA100による98,000原子系の相対計算速度を算出しました。その結果を下図に示します。ここで、CPUの計算速度としては以前のベンチマーク計算の結果を用いました。ただし、CPU × 1の条件では21,600原子系についてのみ計算を行っているため、計算時間が原子数に比例することを仮定して98,000原子系についての計算速度を算出し、それを基準として各相対計算速度を算出しました。下図からは、H100 × 1でCPUの約23倍、H100 × 8でCPUの約150倍の高速化を達成できていることがわかります。
今回のベンチマークでは、Neural Network力場を用いた1 nsの分子動力学計算を10万原子程度の系に対して実施する場合でも、NVIDIA H100を8基使用すれば1日程度で計算を実行できることがわかりました。NVIDIA H100のような高性能のGPUを複数搭載したマシンを使用することで、より現実に近いモデルでのシミュレーションを短い計算時間で高精度に実行できることが期待されます。