[Advance/NeuralMD Pro] Mat3raでのマルチGPUでのベンチマーク#
Mat3ra#
Mat3raはExabyte.io社によって提供されているクラウド環境で、第一原理計算や分子動力学計算などのシミュレーションに特化した計算リソースが用意されています。Amazon AWSおよびMicrosoft Azureが利用可能で、今回は両クラウド環境にてGPU化されたAdvance/NeuralMDのベンチマークを実施しました。 計算リソースの手配にはMat3raの代理店である伊藤忠テクノソリューションズ(CTC)社にご協力頂いております。
Neural Network力場のベンチマーク#
Advance/NeuralMDで作成したNeural Network力場を使って、LAMMPSによる分子動力学計算のベンチマークを実施しました。LAMMPSはGCC11.2.0, OpenBLAS, OpenMPI4.1.1, CUDA11.5でコンパイルしています。
計算に使用した系は、硫化物リチウムイオン伝導体Li10GeP2S12のスーパーセルモデルです(下図)。原子数は21,600個であり、Neural Network力場を適用するには比較的に大きな系になります。Neural Network力場および分子動力学計算の計算条件は下表の通りです。100ステップのMD計算実施後に計算時間を計測しています。

| 計算条件 | 設定値 |
|---|---|
| 対称関数の種類 | Chebyshev多項式 |
| 対称関数の動径成分 | 50個 |
| 対称関数の角度成分 | 30個 |
| カットオフ半径 | 6.0 Å |
| Δ-NNP法 | 適用有り |
| NNの構造 | 2層 x 40ノード(twisted tanh) |
| アンサンブル | NVT (T = 500K) |
| 時間刻み | 0.5 fs |
| MDステップ数 | 100 |
Amazon AWSでのベンチマーク結果#
AWSでの計算条件および計算時間は下表の通りです。CPUのみ、および、GPUを1〜8デバイス使用した場合の5ケースにて計算しています。1GPUデバイス当たり、4つのMPIプロセスを起動しています。
| CPUのみ | GPU x 1 | GPU x 2 | GPU x 4 | GPU x 8 | |
|---|---|---|---|---|---|
| ジョブ Queue |
OFplus | GOF | G4OF | G4OF | G8OF |
| CPU種別 | Intel Xeon Platinum / 72core | Intel Xeon E5-2686-v4 | |||
| GPU種別 | - | NVIDIA V100 | |||
| MPI プロセス数 |
72 | 4 | 8 | 16 | 32 |
| OpenMP スレッド数 |
1 | 2 | 2 | 2 | 2 |
| GPU デバイス数 |
- | 1 | 2 | 4 | 8 |
| 計算時間 / sec |
150.8 | 21.6 | 11.2 | 6.9 | 3.9 |
CPUでの計算速度を1とした相対計算速度を下図に示します。

Microsoft Azureでのベンチマーク結果#
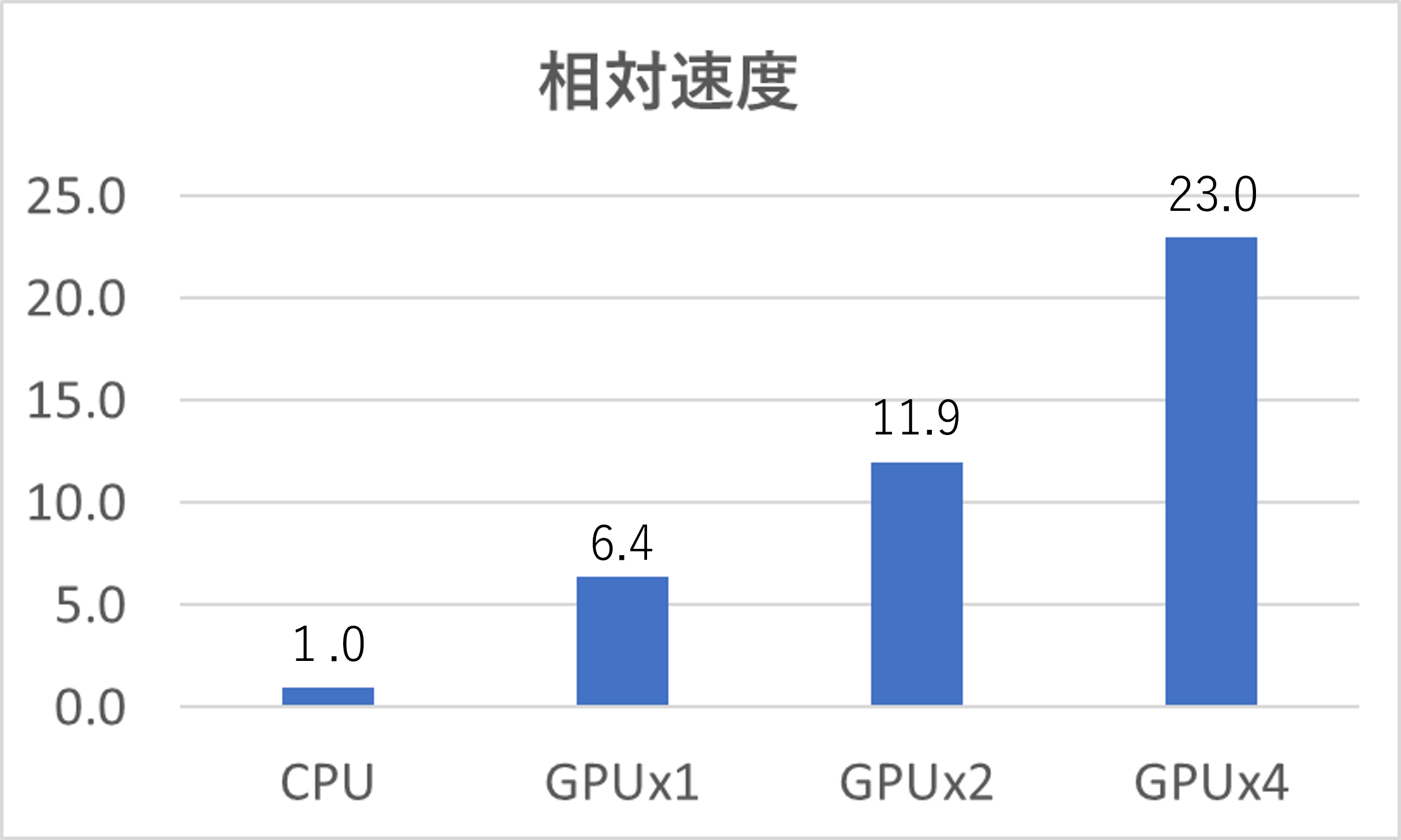
Azureでの計算条件および計算時間は下表の通りです。CPUのみ、および、GPUを1〜4デバイス使用した場合の4ケースにて計算しています。1GPUデバイス当たり、3つのMPIプロセスを起動しています。
| CPUのみ | GPU x 1 | GPU x 2 | GPU x 4 | |
|---|---|---|---|---|
| ジョブQueue | OFplus | GPOF | GP2OF | GP4OF |
| CPU種別 | Intel Xeon Platinum 8168 / 44core | Intel Xeon E5-2690-v4 | ||
| GPU種別 | - | NVIDIA P100 | ||
| MPIプロセス数 | 44 | 3 | 6 | 12 |
| OpenMPスレッド数 | 1 | 2 | 2 | 2 |
| GPUデバイス数 | - | 1 | 2 | 4 |
| 計算時間 / sec | 195.4 | 30.5 | 16.4 | 8.5 |
CPUでの計算速度を1とした相対計算速度を下図に示します。
まとめ#
- Amazon AWSではGPU(NVIDIA V100)1デバイスで、Intel Xeon Platinumの7.0倍ほど高速化されました。
- Microsoft AzureではGPU(NVIDIA P100)1デバイスで、Intel Xeon Platinumの6.4倍ほど高速化されました。
- AWSおよびAzureともに、GPUのデバイス数を増やすと計算速度は十分に良くスケールすることが確認されました。
- 今回のベンチマークに使用した2万原子系ではGPUが4デバイスほどあれば十分に実用的な計算が実施できることが確認できました。原子数が5000以下であれば、GPU1デバイスでも十分高速にMD計算が実施できるものと推測されます。