[Advance/NeuralMD Pro] Benchmarks on the machine with 8 NVIDIA H100 GPUs#
We made benchmarks of molecular dynamics (MD) calculation using Neural Network Potential via LAMMPS on the machine with 8 NVIDIA H100 GPUs. We executed MD calculations for 21,600 atom and 98,000 atom supercell models of sulfide-type lithium ion conductor Li10GeP2S12 used in benchmarks on the cloud with 32 NVIDIA A100 GPUs. Also, we compared the results of the H100 with those of the A100 and the CPU alone.
Calculation Environment and MD calculation conditions#
We show the spec for the machine below.
- CPU:AMD EPYC 9554 (64 cores) × 2
- GPU:NVIDIA H100 × 8
- Compiler:GCC
- MPI library:OpenMPI
- Linear algebra operation libraries:OpenBLAS
- CUDA:12.2
HPC Systems cooperated in the preparation and use of the computing environment.
MD calculations were executed for 100 steps, and the time step was 0.5 fs. Moreover, we estimated the durations to execute similar MD simulations for 1 ns from the calculation results.
Optimization of the number of CUDA threads and MPI processes#
At first, we set number of CUDA threads as 256 and number of MPI processes on each GPU device as 4 in the same way as benchmarks on the cloud with 32 NVIDIA A100 GPUs. In this calculation condition, the parallelization efficiency and calculation speed were lower than expected, so we tried optimizing the number of CUDA threads and MPI processes. After optimization, we concluded the appropriate number of CUDA threads is 128 and the appropriate number of MPI processes on each GPU device is 16.
The results before and after optimization are shown in the table below. In each cell of the table, the upper row corresponds to after optimization, and the lower row (in round brackets) corresponds to before optimization. We can see that the optimization greatly improves calculation speed for the 98,000 atom system from the table. On the other hand, calculation speed for the 21,600 atom system in the optimized GPU × 4 and GPU × 8 conditions is slower than before optimization. It is thought that the excessive number of MPI processes relative to the size of the system causes the reduction in speed.
| GPU × 1 | GPU × 2 | GPU × 4 | GPU × 8 | |
|---|---|---|---|---|
| CUDA threads |
128 (256) |
128 (256) |
128 (256) |
128 (256) |
| MPI processes |
16 (4) |
32 (8) |
64 (16) |
128 (32) |
| Calculation time (sec) (21,600 atoms) |
6.98 (9.20) |
4.09 (4.85) |
2.82 (2.77) |
2.18 (1.47) |
| Calculation time (sec) (98,000 atoms) |
29.45 (41.52) |
14.65 (21.84) |
7.85 (12.53) |
4.57 (6.37) |
| day/ns (21,600 atoms) |
1.62 (2.13) |
0.95 (1.12) |
0.65 (0.64) |
0.50 (0.34) |
| day/ns (98,000 atoms) |
6.82 (9.61) |
3.39 (5.06) |
1.82 (2.90) |
1.06 (1.47) |
Comparison of H100 and A100#
The results for H100 and for A100 are shown in the table below. In each cell of the table, the upper row corresponds to H100, and the lower row (in round brackets) corresponds to A100. The results for H100 is after optimization of the number of CUDA threads and MPI processes.
In GPU × 1 and GPU × 2 conditions, H100 achieves about twice the calculation speed of A100 for the 21,600 atom system. Meanwhile, in GPU × 8 condition, the calculation speeds of H100 and A100 are almost the same for the 21,600 atom system. These results means that the sufficient acceleration cannot be expected when the size of the system to be computed is small. On the other hand, we can see that H100 is about 2.2 to 2.4 times faster than A100 for the 98,000 atom system in any of the conditions.
| GPU × 1 | GPU × 2 | GPU × 4 | GPU × 8 | |
|---|---|---|---|---|
| CUDA threads |
128 (256) |
128 (256) |
128 (256) |
128 (256) |
| MPI processes |
16 (4) |
32 (8) |
64 (16) |
128 (32) |
| Calculation time (sec) (21,600 atoms) |
6.98 (15.35) |
4.09 (7.84) |
2.82 (4.16) |
2.18 (2.29) |
| Calculation time (sec) (98,000 atoms) |
29.45 (69.12) |
14.65 (35.64) |
7.85 (18.08) |
4.57 (9.84) |
| day/ns (21,600 atoms) |
1.62 (3.55) |
0.95 (1.82) |
0.65 (0.96) |
0.50 (0.53) |
| day/ns (98,000 atoms) |
6.82 (16.00) |
3.39 (8.25) |
1.82 (4.19) |
1.06 (2.28) |
Comparison with CPU#
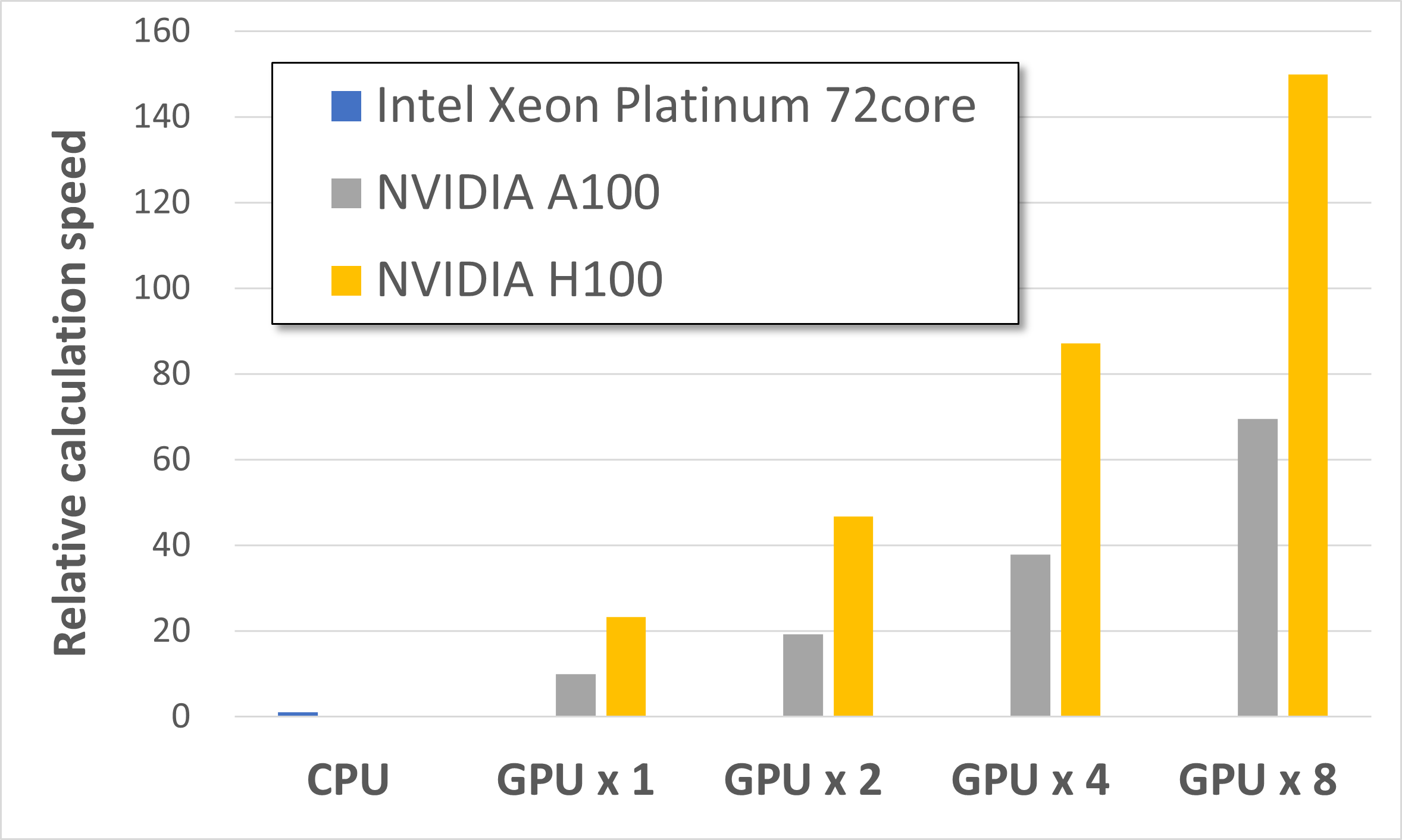
We show the relative calculation speed of H100 and A100 for the 98,000 atom system to the calculation executed by 1 CPU device (Intel Xeon Platinum/72core) on AWS below. We used the result of benchmarking on Mat3ra as the calculation speed of CPU. However, we didn't executed calculation of the 98,000 atom system using 1 CPU device on AWS. So, we estimated the calculation time for the 98,000 atom system from the result of the 12,600 atom system assuming that calculation time is proportional to the number of atoms. We can see that the calculation is accelerated about 23 times faster with H100 × 1, and about 150 times faster with H100 × 8 from the figure below.
The results of benchmarking show that the MD calculation of the system including about 100,000 atoms for 1 ns using Neural Network Potential can be performed in about a day using 8 NVIDIA H100 GPUs. Parallelization with high performance GPUs such as NVIDIA H100 will enable you to execute MD simulations of more realistic models with short calculation time and high accuracy.