[Advance/NeuralMD Pro] Benchmarks of multi-GPU environments on Mat3ra#
Mat3ra#
Mat3ra is a cloud environment provided by Exabyte.io, which provides computational resources specialized for simulations such as first principles calculation and molecular dynamics calculation. Amazon AWS and Microsoft Azure are available, so in this time, we make a benchmark of GPU-accelerated Advance/NeuarlMD on both of the clouds. We are cooperating with ITOCHU Techno-Solutions Corporation (CTC), a Mat3ra agent, to arrange computational resources.
Benchmark of Neural Network Potential#
Using a Neural Network Potential (NNP) made with Advence/NeuralMD, we made benchmark of Molecular Dynamics (MD) calculation with LAMMPS. LAMMPS is compiled using GCC11.2.0, OpenBLAS, OpenMPI4.1.1, CUDA11.5.
The system used for the calculation is the supercell model of sulfide-type lithium ion conductor Li10GeP2S12 (the below figure). The number of atoms are 21600 which is relatively large system to apply NNPs. The calculation conditions of the NNP and the MD calculation are shown in the below table. The calculation times were measured after running the 100 step MD calculation.

| Calculation Condition | Set Value |
|---|---|
| Symmetric Function | Chebyshev Polynomial |
| Radial Component of Symmetric Function |
50 |
| Angular Component of Symmetric Function |
30 |
| Cut-off Radius | 6.0 Å |
| Δ-NNP Method | Enabled |
| Structure of NN | 2 layers x 40 nodes (twisted tanh) |
| Ensemble | NVT (T = 500K) |
| Time Step | 0.5 fs |
| MD Step Number | 100 |
Results of Benchmark on Amazon AWS#
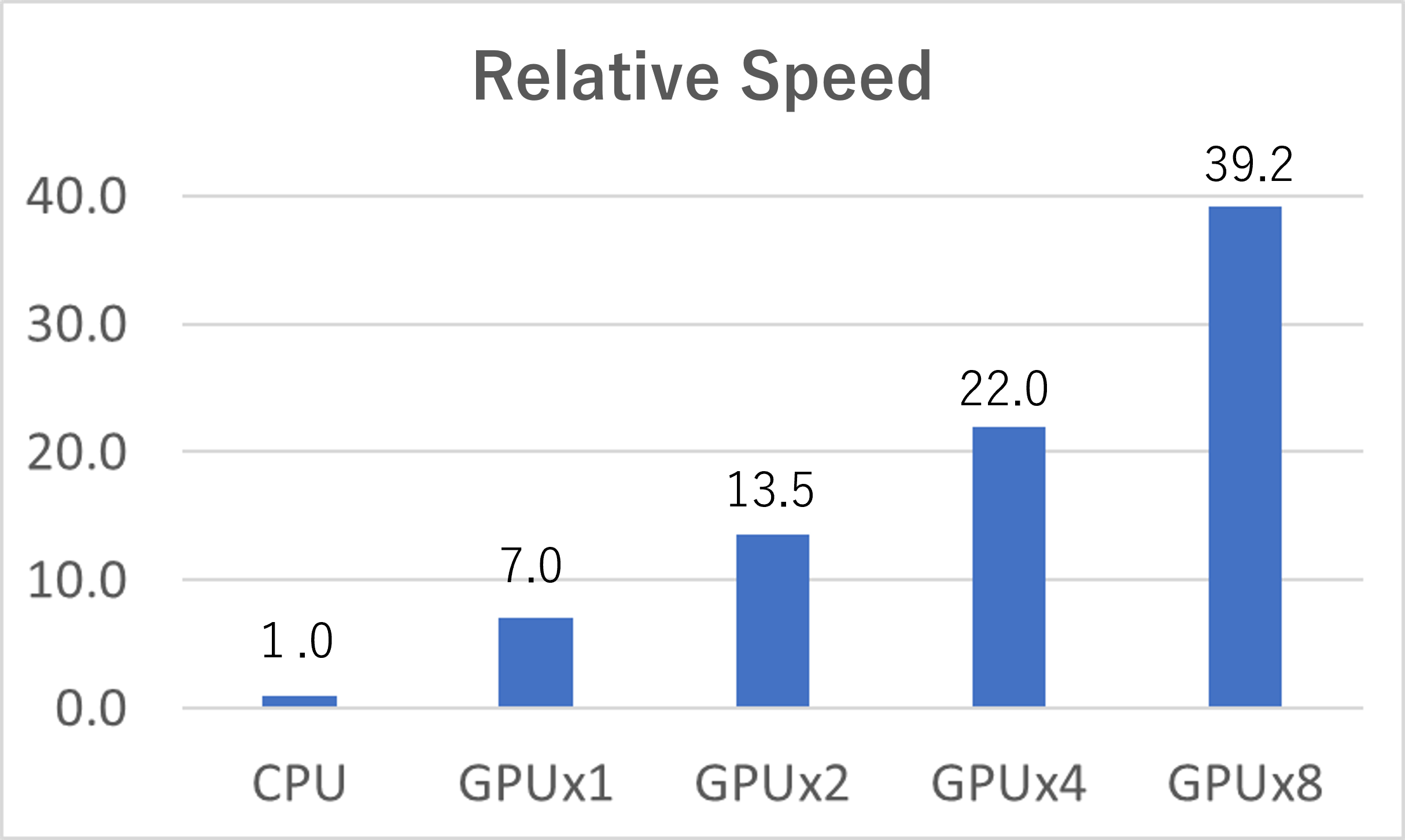
The calculation conditions and times on AWS are shown in the below table. The calculation ran on 5 cases which used only CPU and 1 – 8 GPU devices. 4 MPI processes were activated per 1 GPU device.
| only CPU | GPU x 1 | GPU x 2 | GPU x 4 | GPU x 8 | |
|---|---|---|---|---|---|
| Job Queue |
OFplus | GOF | G4OF | G4OF | G8OF |
| CPU Type | Intel Xeon Platinum / 72core | Intel Xeon E5-2686-v4 | |||
| GPU Type | - | NVIDIA V100 | |||
| MPI Processes |
72 | 4 | 8 | 16 | 32 |
| OpenMP Threads |
1 | 2 | 2 | 2 | 2 |
| GPU Devices |
- | 1 | 2 | 4 | 8 |
| Calculation Time / sec |
150.8 | 21.6 | 11.2 | 6.9 | 3.9 |
The relative calculation speed when that using only CPU equal to 1 is shown in below figure.
Benchmark on Microsoft Azure#
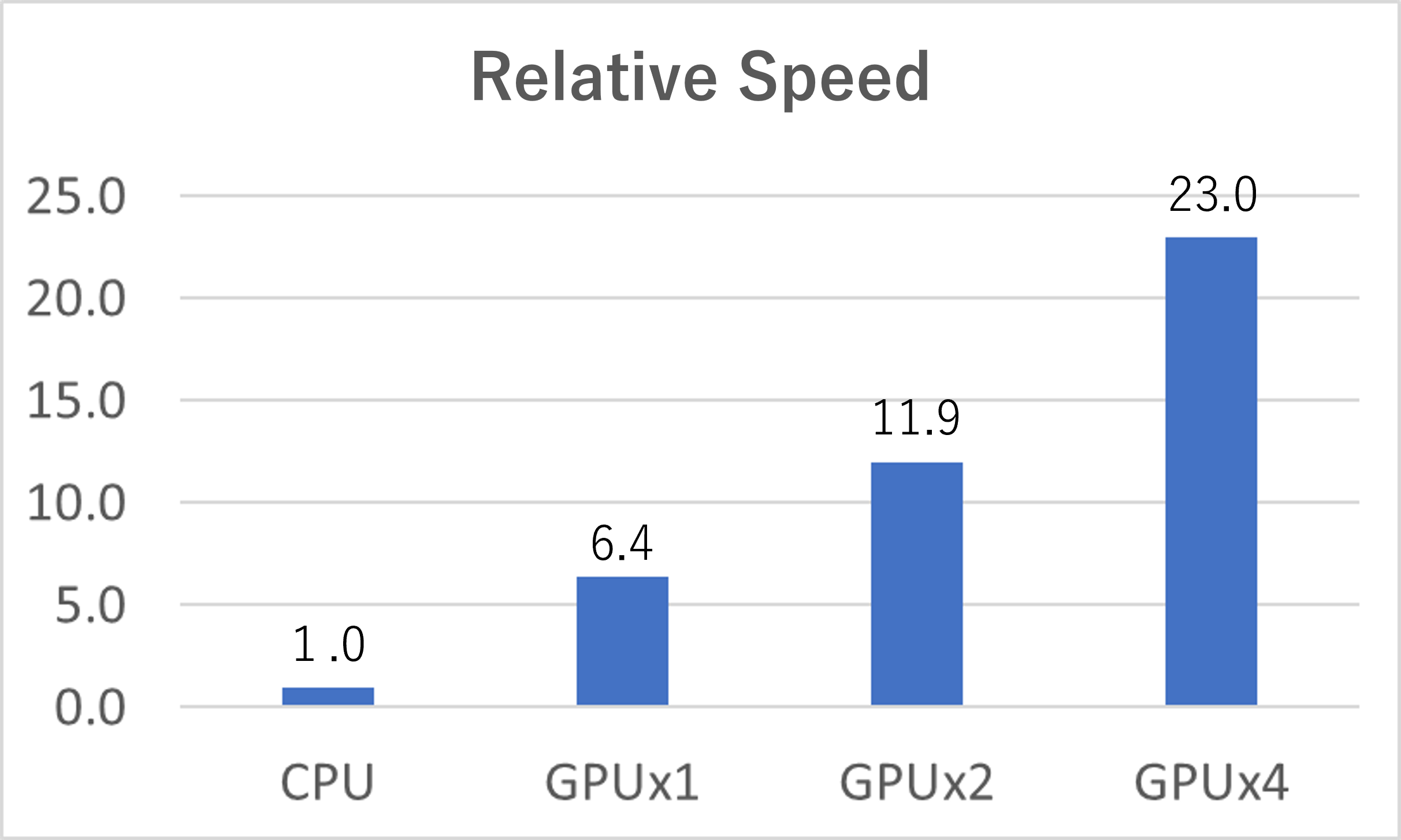
The calculation conditions and times on Azure are shown in the below table. The calculation ran on 5 cases which used only CPU, and 1 – 4 GPU devices. 3 MPI processes were activated per 1 GPU device.
| only CPU | GPU x 1 | GPU x 2 | GPU x 4 | |
|---|---|---|---|---|
| Job Queue | OFplus | GPOF | GP2OF | GP4OF |
| CPU Type | Intel Xeon Platinum 8168 / 44core | Intel Xeon E5-2690-v4 | ||
| GPU Type | - | NVIDIA P100 | ||
| MPI Processes | 44 | 3 | 6 | 12 |
| OpenMP Threads | 1 | 2 | 2 | 2 |
| GPUデバイス数 | - | 1 | 2 | 4 |
| Calculation time / sec | 195.4 | 30.5 | 16.4 | 8.5 |
The relative calculation speed when that using only CPU equal to 1 is shown in below figure.
Conclusion#
- On Amazon AWS, using 1 GPU device, the calculation was about 7.0 times faster than Intel Xeon Platinum.
- On Microsoft Azure, using 1 GPU device, the calculation was about 6.4 times faster than Intel Xeon Platinum.
- It is made sure of that the calculation speed is increased enough along with increasing GPU devices in both of AWS and Azure.
- In the 20000 atoms system such as used this benchmark, it can confirm that practical calculation can be sufficiently performed using 4 GPU devices. If the number of atoms is under 5000, it can run fastly with 1 GPU device.