[Advance/NeuralMD Pro] Neural Network力場のGPU化#
2022年9月に、Advance/NeuralMDをGPU化したAdvance/NeuralMD Proをリリースする。Neural Networkの学習過程およびLAMMPSでの分子動力学計算がGPU化されており、いずれもMPIと併用することでマルチGPUおよびマルチノードのマシン環境に対応している。この記事では、GPU化の仕組みを紹介する。GPUによるベンチマーク結果については、別記事にて紹介する。
関連記事:
Neural Network力場の計算手続き#
Neural Network力場の計算では、下図のような多層パーセプトロンを用いた手続きにてエネルギーおよび力を計算する。
先ずは、①対称関数および隣接原子座標による微分を計算する。これを②順方向に伝搬させてエネルギーを計算した後、③逆方向への伝搬にて微分を計算する。最後に、④隣接原子間でを計算して原子𝑖が𝑗に及ぼす力を計算する。
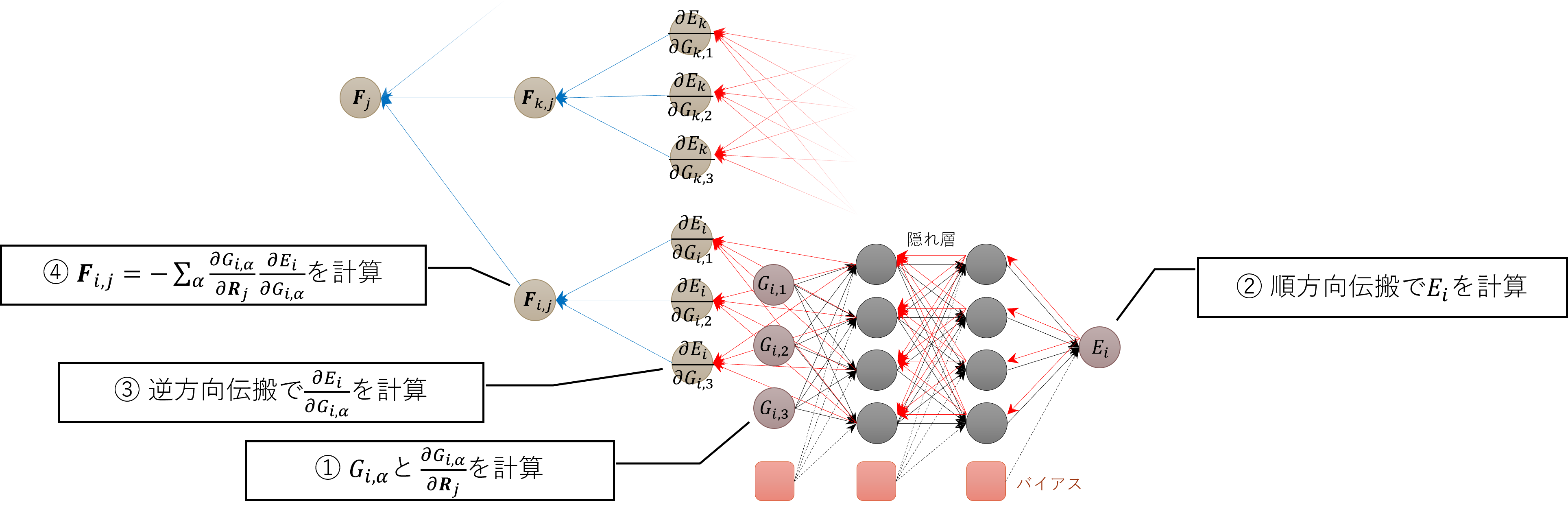
最も計算コストが高いのは、①の対称関数とその微分の計算である。②および③のNeural Network内の伝搬過程は行列‐行列の積(Level-3 BLAS)にて遂行されるのだが、他の処理に比べると計算コストは極めて低い。
④は対称関数に次いで2番目に計算コストが高い。はを固定することで、を行列、をベクトルとしてLevel-2 BLASにて計算される。原子に働く力は、ニュートンの第三法則を適用することで
と計算される。最右辺の通り、は明示的に計算する必要はない。また、はビリアル応力の計算にも利用される。
さらに、Neural Networkの学習過程においては、⑤力の誤差を計算する必要がある。力はNeural Networkの一階微分として計算されるため、その誤差を計算するには二階微分が要求される。この二階微分の計算には多数回のLevel-2およびLevel-3 BLASが実行されるため、④以上の計算コストが掛かり、学習過程における計算時間の90%以上を占める。
Neural Networkの学習過程においては、最初に一度だけ全ての構造における対称関数とその座標微分を計算する(①)。その後、各エポックにおいて②〜⑤の処理を実行してエネルギーおよび力の誤差を計算する。①についてはGPU化しているのだが、計算回数がただ一度だけなので計算時間全体の短縮には大きく寄与しない。重要なのは、②〜⑤の高速化を図ることである。ただし、②および③は元より低コストであるため、GPU化はせずにホスト側(CPU)で処理する。④は最大のボトルネックでは無いものの、無視できない程度の計算時間を要する。しかしながら、学習過程においてはのデータ容量が大きく(100 GB以上となることもある)、GPUのグローバルメモリーに載せることは難しい。このため、最大のボトルネックであるNeural Networkの二階微分の計算(⑤)のみをGPU化する。⑤はLevel-2およびLevel-3 BLASの計算であるため、cuBLASを使うことで容易にGPU化できる。
学習過程のGPU化#
②〜④はCPUで処理され、⑤はGPUで処理される。⑤がGPUで高速化されたことにより、②〜④の計算時間も無視できなくなる。このため、そのまま計算を実行すると十分な高速化が期待できない可能性がある。そこで、MPIによるプロセス並列を併用することでさらなる性能向上を図る。例えば、MPIで4プロセスを起動した場合、1エポック当たり各プロセスは下図のように動作する。エポックの開始から⑤が完了するまでプロセス間の通信が存在しないため、この間は各プロセスは非同期で動作できる。そうすると、あるプロセスがCPUで処理している間に別のプロセスがGPUにて計算を実施するという状況が起こる。GPUに対して物理コア数を超過するスレッド数を流すことでGPUの稼働率が上昇し、相対的にCPUでの処理時間を低減できる。その結果、学習過程全体が十分に高速化される。経験上、GPU1デバイス当たり 2〜4つのMPIプロセスがあれば十分である。また、CPUにおける処理はOpenMPでスレッド並列されている(つまり、CPUにおいてはMPI+OpenMPハイブリッド並列である)。

LAMMPSによるMD計算のGPU化#
学習済みのNeural Network力場を使ってMD計算を実施するときも計算コストが高いため、GPUによる高速化が必要である。Advance/NeuralMDではMD計算にLAMMPSを使用している。Neural Network力場の計算部分は当社独自実装である。MD計算では、各MDステップにおいて①〜④の処理が必要である。学習過程と同様に②と③はCPUで処理する。対称関数の計算(①)と力の計算(④)をGPU化する。のデータ容量は学習過程に比べると大きくないため、①で生成したをGPUのグローバルメモリーに保持したまま、④の計算にて利用する。当該データはGPU内部だけで扱われるため、ホストへの転送は不要である。MD計算では①が最大のボトルネック(計算時間の95%以上)であるが、対称関数の計算はGPUとの相性が良く大幅な高速化が期待できる。また、学習過程と同様に、1デバイス当たり2〜4プロセスのMPI並列を適用することで計算効率が向上する。

対称関数計算のGPU化#
対称関数の計算をGPU化する方法を紹介する。対称関数には動径成分と角度成分があるのだが、先ずはについて説明する。 は一般に
として計算される。 右辺は全ての隣接原子についての総和である。原子座標についての微分は
である。であれば、およびをそれぞれCUDAのブロックおよびスレッドに割り当てることで容易にGPU化できる。対称関数の自由度については、ブロック当たりのスレッド数が適切な値となるようにを因数分解しておよびに直積される。また、の場合にはスレッド間の依存関係が発生するのだが、当該項はあえて計算しないことで性能向上を図る。当該項は明示的に計算せずとも、によりニュートンの第三法則が成り立つため、事後的にその寄与を取り込むことが出来るのである。
次に、角度成分について説明する。の計算には少々の工夫が必要である。は一般に
として計算される。 右辺の内側の総和によりとに依存関係が生じるため、GPU化が難しい。そこでの関係を利用して、
のように式を変形する。計算量は2倍となるものの、との依存関係が消失する。微分については
となる。そうすると状況は動径成分の場合と同様である。つまり、をCUDAのブロック、をCUDAのスレッドに割り当てるのである。ただし、各スレッドはおよびの計算を担当する。スレッド内でに関するループがあるのだが、ループの内部で各スレッドが全てのにアクセスする。はと等価であるため、各ブロックにてを共有メモリーに載せることでグローバルメモリーへのアクセス頻度を低減させて高速化を図る。また、の場合におけるの計算においても、動径成分の場合と同様にニュートンの第三法則が利用できる。
対称関数がChebyshev多項式の場合、漸化式の形式で計算するとに関する依存関係が発生するため、あえてコサインを使って非効率に計算することでGPU化しやすくするという工夫も必要である。