[Advance/NeuralMD Pro] GPU Acceleration of Neural Network Potential#
On September 2022, GPU accelerated Advance/NeuralMD: Advance/NeuralMD Pro will be released. The training processes for Neural Network and the Molecular Dynamics calculations with LAMMPS are accelerated, and all of them support multi-CPU or multi-node machine environments by using in conjunction with MPI. In this article, we introduce the mechanism of GPU acceleration. The results of benchmarks with GPU are introduced in other articles.
Related Articles:
- [Advance/NeuralMD Pro] Benchmarks of acceleration by GPU
- [Advance/NeuralMD Pro] Benchmarks of multi-GPU environments on Mat3ra
Calculation procedure of Neural Network Potential#
On the calculation of Neural Network Potential (NNP), the energies and forces are calculated on procedure like shown in below using multi-layer perceptron.
At first, ① calculate differential of the symmetric functions and neighboring atomic coordinations . Using this, after ② calculation of energies by feed-forward propagation, ③ calculate differential by backpropagation. Finally, ④ calculate sum and then calculate forces affect from atom to .
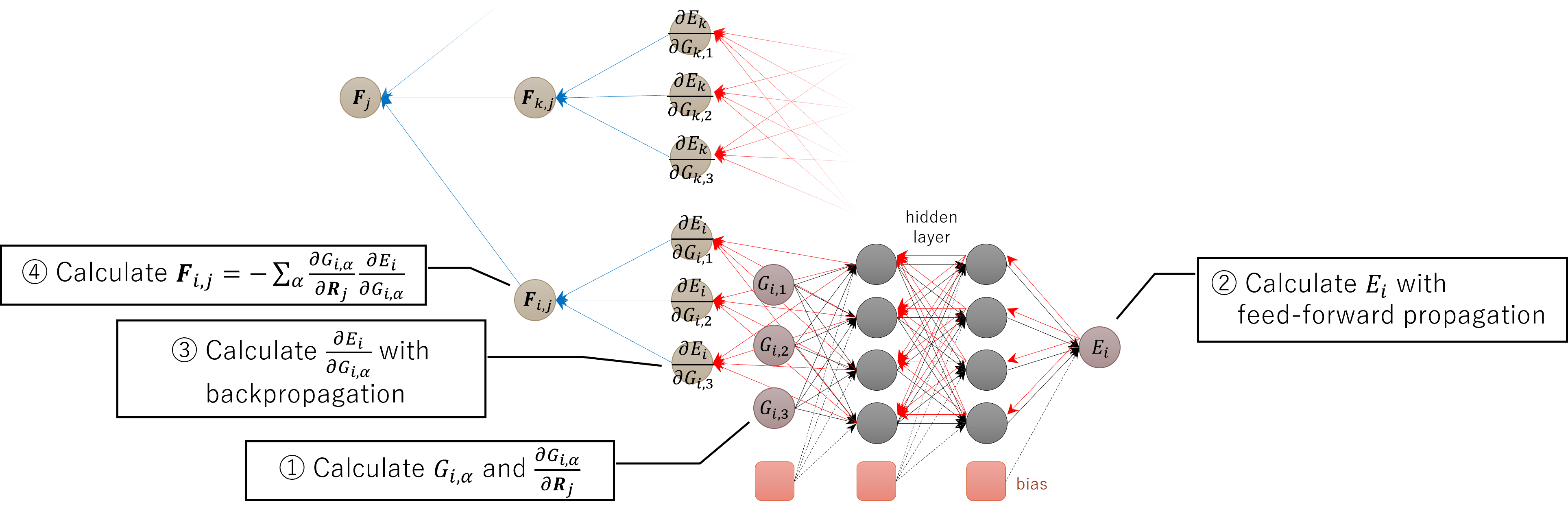
The most expensive process is the calculation of the symmetric functions and its differentials on the process ①. The propagation processes in Neural Network in the process ② and ③ are executed with matrix - matrix product (Level-3 BLAS), but they are extremely inexpensive compared with others.
④ is second most expensive after the calculation of the symmetric functions. By fixing , is calculated with Level-2 BLAS using as matrix and as vector. The force affects atom is calculated by appicating Newton's third law as following;
As the rightmost side, isn't needed to calculate expressly. In addition, is used to calculate the virial stress.
Moreover, in the training processes of Neural Network, ⑤ calculating the error of forces are needed. The forces are calculated as first-order differential of Neural Network, so calculation of second-order differential is needed to calculate error of them. In this differential calculation, due to because a lot of Level-2 and Level-3 BLAS are executed, it is expensive more than 4 and takes more than 90% calculation time of training.
In the training processes of Neural Network, the symmetric functions and its coordinate differentials are calculated only once at the beginning (①). After that, execute the processes ② – ⑤ and calculate the energies and the force errors at each epochs. The process ① has already GPU accelerated, but it doesn't contribute significantly to reduce total calculating time because it runs only once. The important thing is accelerating the processes ② – ⑤. However, since the processes ② and ③ are originally inexpensive, they are executed on host side (CPU) without GPU acceleration. ④ is not the maximum bottleneck, but it takes a lot of time which cannot ignore. However, the data quantity of is too large (sometimes it takes over 100 GB) to load into the global memory of GPU. Because these reasons, only calculation of second-order differential (⑤) is GPU-accelerated. ⑤ is the calculation with Level-2 and Level-3 BLAS, so it can GPU-accelerate easily using cuBLAS.
GPU acceleration of the training processes#
processes ② – ④ will execute on CPU, and ⑤ will execute on GPU. By accelerating ⑤ with GPU, the calculating time of processes ② – ④ will not become negligible. Because of this, acceleration will not expect enough if calculation is executed as it is. Therefore, further performance improvement is planned with using process parallelism by MPI together. For example, If 4 processes activated by MPI, each processes will act as shown below figure per 1 epoch. Since there is no inter-process communication from start of epochs until end of the process ⑤, each processes can run asynchronously. This create a situation that some processes run on GPU during others run on CPU. By passing threads that the number exceeds the number of physical cores to the GPU, the operating rate of GPU is increased and processing time of CPU can be reduce relatively. As a result, the entire processes of training is sufficiently accelerated. From experience, it is enough that there are 2 – 4 MPI processes per 1 GPU device. In addition, the processes on CPU are threaded in parallel by OpenMP (in short, they are in MPI + OpenMP hybrid parallelism in CPU).

Acceleration of MD calculation via LAMMPS#
Since it is expensive that doing MD calculations using the trained NNP, it need GPU accelerating. Advance/NeuralMD is using LAMMPS for MD calculations. The NNP calculation part is our original implementation. In MD calculation, the processes ② – ④ is needed on each MD steps. Like as the training process, ② and ③ are calculated on CPU. The calculations of the symmetric function (①) and the forces (④) are GPU accelerated. The data size of is smaller than that in training processes, is reused on the process ④ with keeping them which generated on the process ① in the global memory of GPU. This data is handled only inside the GPU, so transferring them to the host is not needed. The process ① is the maximum bottleneck (over 95% of the calculation time), but the calculation of the symmetric function is compatible with GPU, so the great acceleration is expected. In addition, similar to the training process, the 2 – 4 process MPI parallelism per 1 GPU device can improve the efficiency of calculation.

GPU acceleration of the symmetric function calculation#
We'll introduce the method of GPU acceleration of the calculation of the symmetric functions. The symmetric functions have the radial and angular component, but explain about at first. Generally, is calculated by
The right side is the summation about the all neighboring atoms . The differential by atomic coordination is
If , it can be GPU accelerated easily by allocating and to the blocks and the threads of CUDA. About the degree of freedom of the symmetric functions , Factorize for the appropriate number of threads per block, and direct product to and . In addition, the inter-thread dependence is occur when , but this term will not be calculated on purpose to improve performance. Even if this term is not explicitly calculated, its contribution can be taken in after the fact because Newton's third law is established by .
Next, we'll explain about the angular component . The calculation of need some devises. Generally, is calculated by
The dependence of and is occur by the summation in the right side, it is difficult to GPU-accelerate. Therefore, using the relation , transform the expression into like the following;
Although the amount of calculation is doubled, the dependence of and will disappear. The differential of this is the following;
If so, the situation is similar to that of the radial component. In short, we allocate to the blocks, and to the threads of CUDA. However, each thread take charge of the calculation and . There is a loop about in the thread, but each thread will access all in the loop. Since is equivalent to , an acceleration is expected with reducing the access frequency to global memory by loading to shared memory. Additionary, about calculation of in the case of , The Newton's third law is usable like the radial component.
If the symmetric function is the Chebyshev polynomial, there is a dependence of when it is calculated in recurrence relation format, so it is also necessary to devise a way to make it easier to use GPUs by daring to calculate inefficiently using cosines.