[Advance/NeuralMD Pro] HPCでのベンチマーク#
NeuralNetwork力場を用いたLAMMPSでの分子動力学計算のベンチマークを実施しました。 計算に用いた系は、以前Mat3raを用いて行ったベンチマークと同じもので、硫化物リチウムイオン伝導体Li10GeP2S12のスーパーセルモデル(21,600原子系)です。
計算機環境#
- CPU:AMD EPYC 7742 64-Core
- GPU:NVIDIA A100 SXM4
計算機環境の用意・使用にあたっては、HPCシステムズ様にご協力いただきました。
また、今回用いたマシンに使用されているAMD製のCPUにはIntel製のコンパイラー・ライブラリは適さないため、コンパイラーにはGCCを、行列演算ライブラリにはOpenBLASを用いました。
ベンチマーク結果#
計算条件および計算結果は下表の通りです。CPUのみ、および、GPUを1〜8デバイス用いた場合の5条件で計算しました。MPI並列数は、1GPUデバイスあたり4つのMPIプロセスが起動されるよう設定しました。
| CPU | GPU x 1 | GPU x 2 | GPU x 4 | GPU x 8 | |
|---|---|---|---|---|---|
| MPI プロセス数 |
64 | 4 | 8 | 16 | 32 |
| OpenMP スレッド数 |
1 | 2 | 2 | 2 | 2 |
| GPU デバイス数 |
- | 1 | 2 | 4 | 8 |
| 計算時間 / sec |
56.4 | 16.0 | 8.3 | 4.4 | 2.5 |
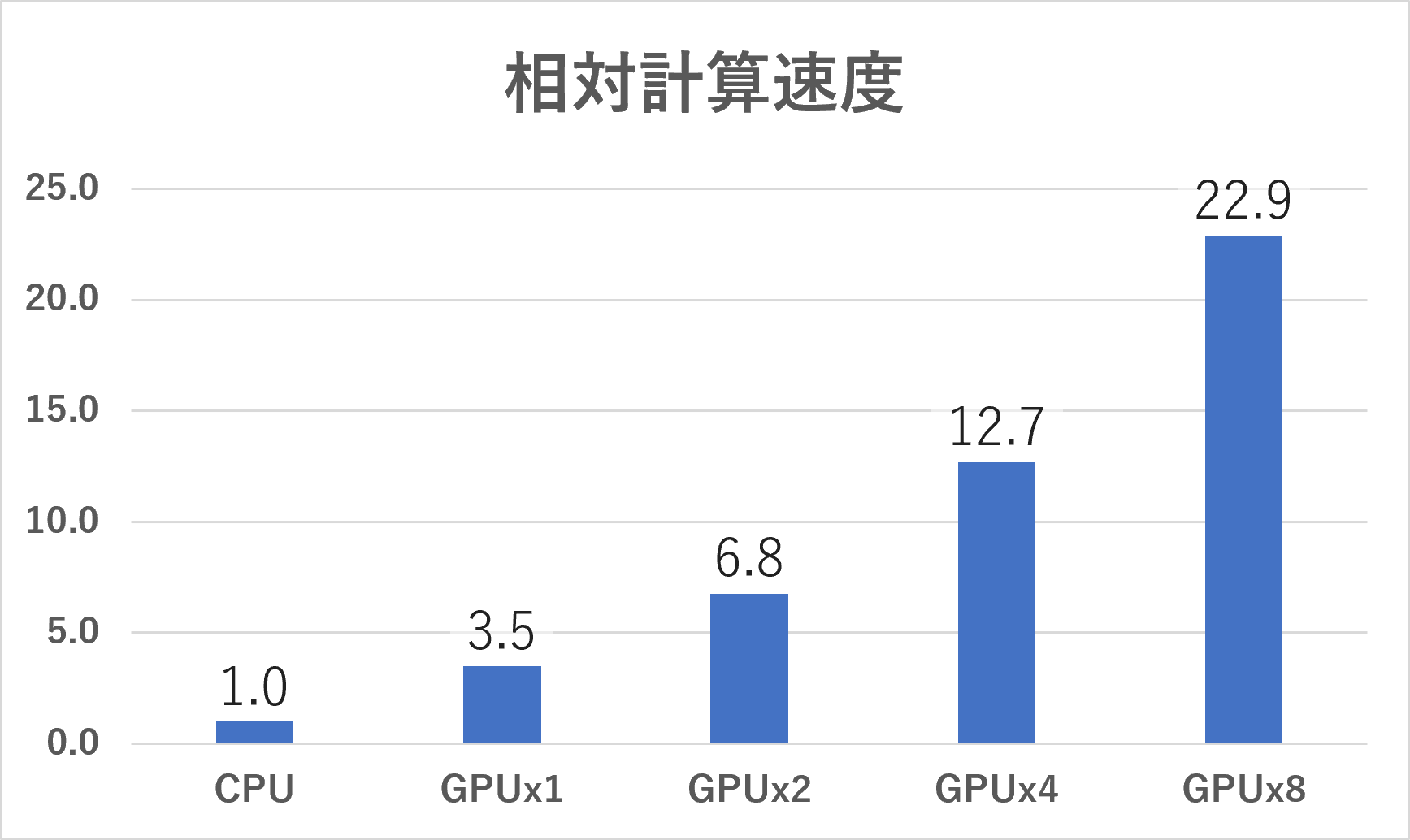
CPUのみの計算速度を1とした相対計算速度を下図に示します。GPU1デバイスで約3.5倍、8デバイスで約22.9倍の高速化が見られました。
クラウド環境との比較#
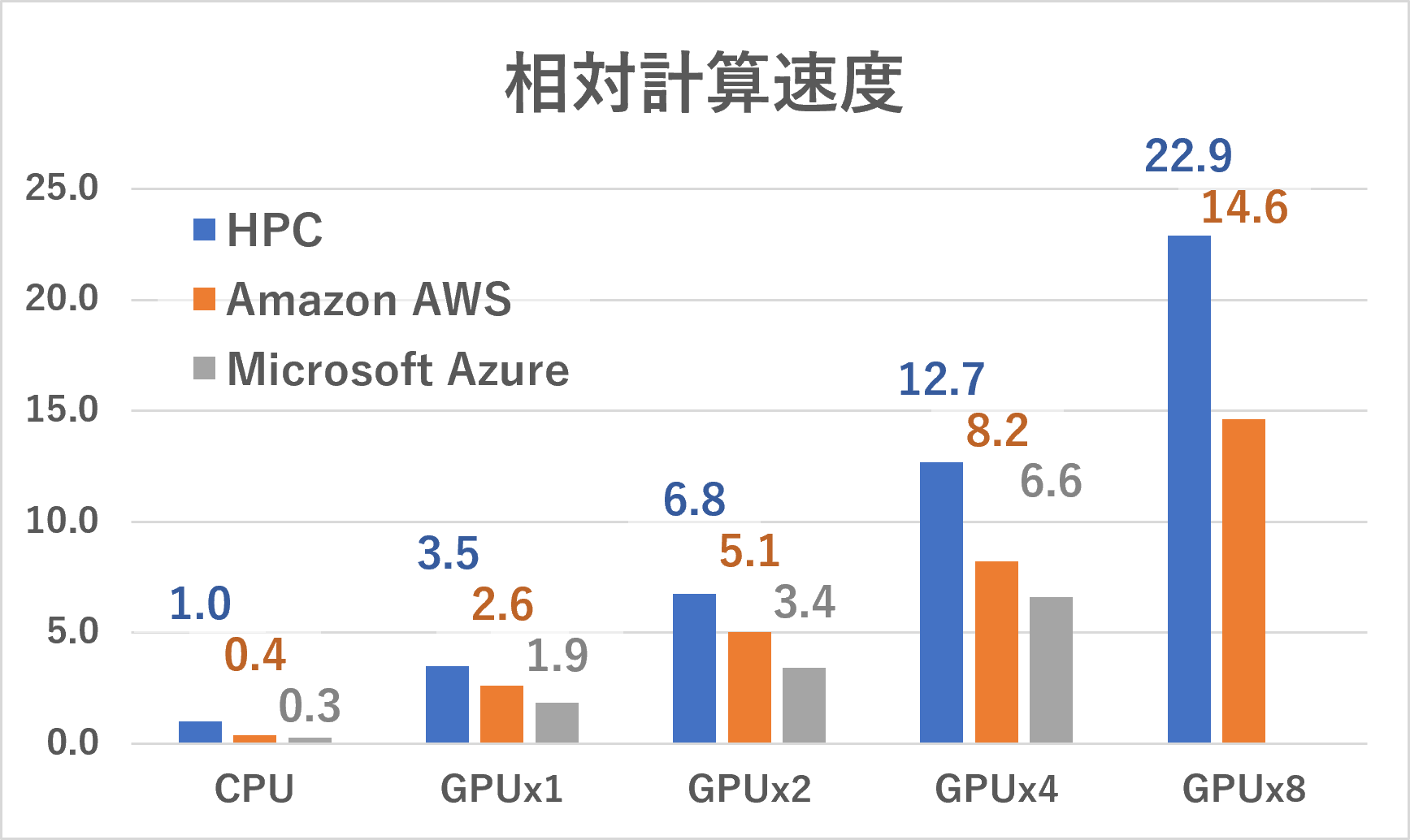
今回の結果と併せて、上図と同じ基準で算出したMat3raのベンチマーク結果の相対計算速度を下図左に示します。Mat3raでは、CPUにIntel Xeon Platinumシリーズ、GPUにはNVIDIA V100またはNVIDIA P100を用いました。その他の条件に関しては該当記事をご参照ください。
CPU単体どうしで比較すると、AMD EPYCは、Intel Xeon Platinumに対して計算速度が3倍ほど高くなりました。AMD EPYCにGPU8デバイスを用いた場合は、Intel Xeon Platinumのそれと比較して1.5倍以上の計算速度が得られました。これをIntel Xeon PlatinumのCPU単体と比較すると、計算速度の差は60倍以上になります。
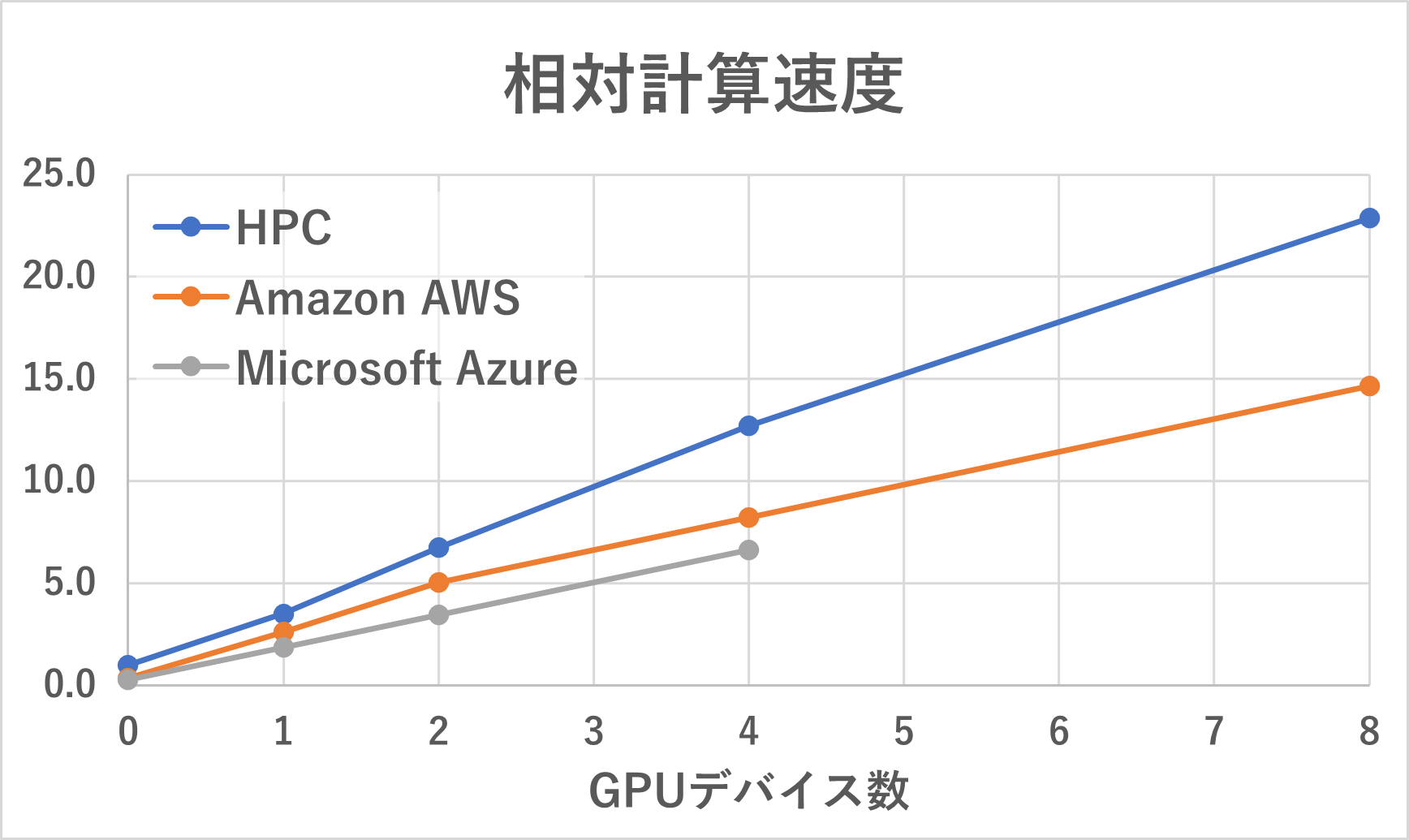
また、結果をGPUデバイス数に対して取ったグラフを下図右に示します。全ての環境において、GPUデバイス数の増加に合わせて、等比的に計算速度が増加していく様子が確認されました。