汎用GNN力場MACE-MPのファインチューニング:Pd-H系の機械学習ポテンシャルの構築#

パラジウム(Pd)は自己体積の数百倍もの水素を吸蔵する能力を持つため、水素吸蔵合金や水素透過膜、触媒反応の基盤材料として重要です。このような系において、水素の拡散挙動や欠陥との相互作用を分子動力学(MD)やモンテカルロ(MC)シミュレーションで解析するには、高精度な原子間ポテンシャルが不可欠です。近年、第一原理計算(DFT)の精度と古典力場の速度を両立する機械学習原子間ポテンシャル(MLIP)が注目を集めていますが、ゼロからモデルを学習させるには膨大な計算データが必要です。本事例では、Materials Projectの巨大なデータベースで事前学習された汎用グラフニューラルネットワーク(GNN)力場である「MACE-MP」を利用し、第一原理計算ソフトウェアAdvance/PHASEとATATを連携させたクラスター展開法で生成した少数のPd-H系のDFTデータを用いてファインチューニングを行いました。これにより、比較的少ない計算リソースと時間で、Pd-H系に特化した実用レベルのMLIPを構築できました。
Keywords: 第一原理計算 (DFT), 機械学習原子間ポテンシャル (MLIP), グラフニューラルネットワーク (GNN), MACE-MP, ファインチューニング, Pd-H合金, 水素吸蔵
理論的背景・手法#
MACE (Message Passing Atomic Cluster Expansion)#
MACE [1] は、原子間の相互作用を多体項として効率的かつ高精度に学習できる最新の同変グラフニューラルネットワーク(Equivariant GNN)です。MACE-MPは、15万以上の無機結晶構造(Materials Project)を用いて事前学習されたファウンデーションモデル(基盤モデル)[2] であり、周期表のほぼ全ての元素に対応しています。
トレーニングデータの準備と学習プロセス#
学習用の参照データとして、ATAT [3] のクラスター展開法の構造最適化過程(.trajファイル)から抽出された非平衡構造データを利用しました。各構造におけるエネルギー(Energy)、力(Force)、応力(Stress)のDFT計算には、Advance/PHASEを用いています。隣接する最適化ステップ間で構造が類似しすぎないよう適切に間引き処理を行い、過学習を防止しています。
- データセット構成: H(原子番号1)とPd(原子番号46)からなる合計881構造。
- 分割: 学習用(Train)704構造、検証用(Validation)177構造。
- 学習環境: CPU環境(28スレッド) を使用し、バッチサイズ4、最大100エポックで学習を実行しました。
MACE-MPのファインチューニング結果と考察#
1. ベースモデル(事前学習済みモデル)の予測精度#
まず学習前のベースモデル(MACE-MP, medium)を用いて、今回準備した検証用データのエネルギーと力を予測しました。 第一原理計算では、ソフトウェアや擬ポテンシャルの違いにより、エネルギーの絶対値(ゼロ点)にシステム依存の巨大な定数ズレが生じます。そのため、PdとHそれぞれの基準エネルギーのシフト量(オフセット)を最小二乗法で算出し、予測値から差し引いた「相対エネルギー」を用いて評価を行いました。
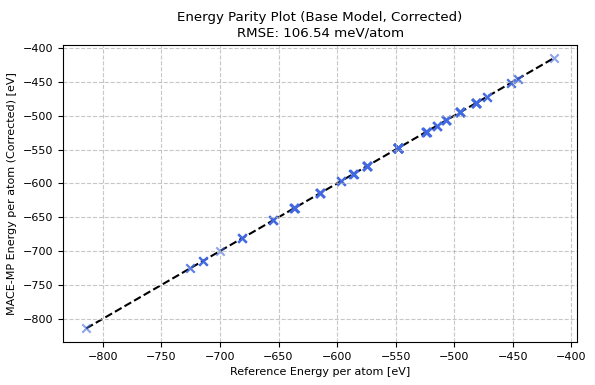
図1. ベースモデルによるエネルギーのパリティプロット(オフセット補正後)
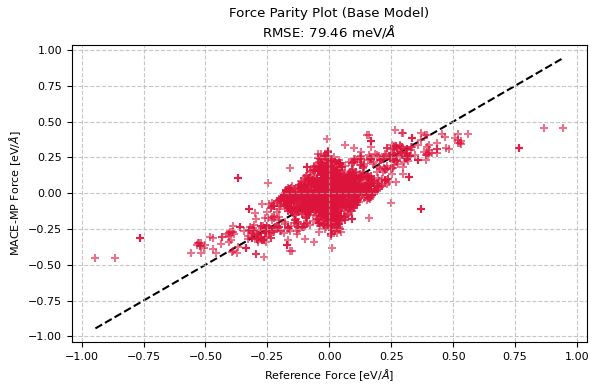
図2. ベースモデルによる力のパリティプロット
図1および図2より、ベースモデルの時点でもPd-H系の物理的な傾向は大まかに捉えられているものの、エネルギーのRMSEは 106.5 meV/atom、力のRMSEは 79.5 meV/Å となっており、特にMD計算の安定性に直結する力(Force)のばらつきが大きいことが分かります。
2. ファインチューニングの学習曲線(LossとRMSEの推移)#
学習は2つのステージに分けて自動的に実行されました(図3)。Stage 1(0〜69エポック)ではMD計算の安定性に直結する「力(Force)」の学習に重点が置かれ、Stage 2(70エポック以降)では「エネルギー(Energy)」の重みが引き上げられるとともに、Stochastic Weight Averaging(SWA)による重みの平均化が行われました。
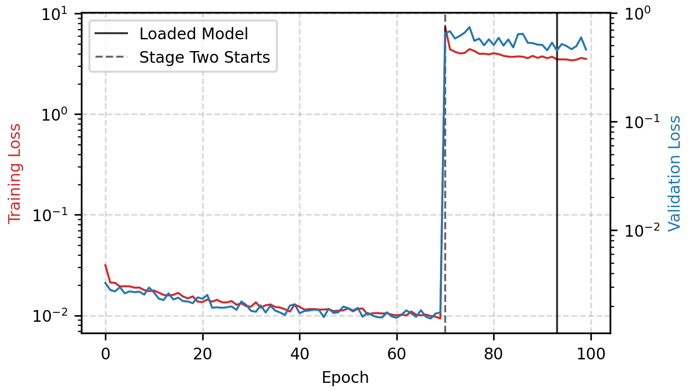
図3. Training Loss と Validation Loss の推移
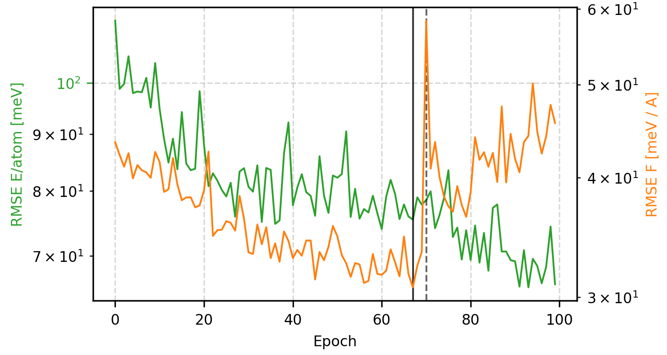
図4. エネルギーと力の RMSE の推移
図4の予測誤差(RMSE)の推移を確認すると、70エポック目で損失関数の重みがエネルギー偏重に変更されたことに伴い、Force(力)のRMSEが一時的に上昇し、その後40〜50 meV/Åの範囲で推移しています。これはStage 2において、モデルがエネルギー精度の向上(SWAによる汎化)にフォーカスしたための正常なトレードオフの挙動です。ForceのRMSEは微増したものの、依然として実用的な閾値とされる50 meV/Å以下の高い精度を維持しています。
3. ファインチューニング後の予測精度(パリティプロット)#
学習完了後のモデルを用いて、DFT計算による参照値(横軸)とMACEによる予測値(縦軸)の相関を再度評価しました。
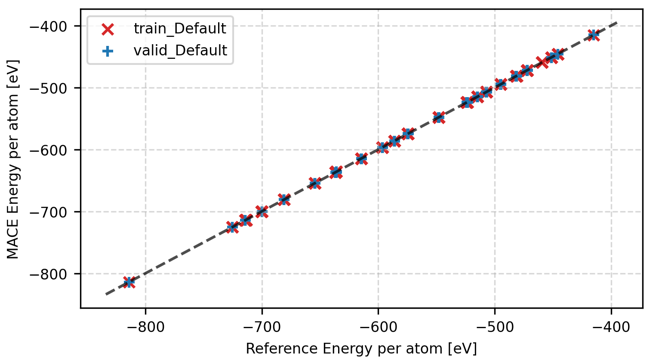
図5. ファインチューニング後のエネルギーパリティプロット (eV/atom)
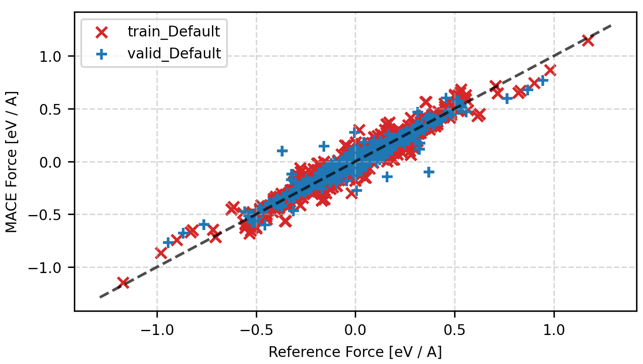
図6. ファインチューニング後の力パリティプロット (eV/Å)
図5のエネルギーパリティプロットでは、学習用・検証用データともにほぼ理想的な対角線上にプロットされており、RMSEが大幅改善されています。図6の力パリティプロットにおいても、ベースモデル(図2)と比較すると、散布図のばらつきが大幅に改善されていることが確認できます。
表1. 最終的なモデルの精度(検証用データ)
| 評価項目 | ベースモデル | Stage 1 モデル (Epoch 67) | Stage 2 モデル (Epoch 93, SWA) |
|---|---|---|---|
| Energy RMSE (meV/atom) | 106.5 | 75.4 | 65.6 |
| Force RMSE (meV/Å) | 79.5 | 30.7 | 44.2 |
表1に示す通り、学習の各ステージで異なる特性を持つモデルが得られました。Stage 1(Epoch 67)のモデルは、Force RMSEが 30.7 meV/Å と非常に高精度であり、MDシミュレーションにおいて原子軌跡の解析に適しています。一方、Stage 2(Epoch 93)のモデルは、Force精度を 44.2 meV/Å に保ちつつ、Energy RMSEを 65.6 meV/atom まで改善しており、相安定性の評価など、エネルギーの計算精度が重要となる解析に適しています。いずれのモデルも、実用レベルとされる 50 meV/Å を下回る優れた精度を達成しています。
まとめ#
本事例では、第一原理計算ソフトウェアAdvance/PHASEのDFT計算データを用いて、MACE-MP力場のファインチューニングを行いました。構造最適化過程という限られた非平衡データセットを用いたにもかかわらず、事前学習済みモデル(MACE-MP)を活用することで、短時間かつ少ない計算リソースで実用レベル(Force RMSE < 50 meV/Å)のPd-H系力場を構築できました。本モデルはそのまま標準的なMDシミュレーションに適用可能ですが、今後は高温環境下でのMDトラジェクトリなどをアクティブラーニング等で追加学習させることで、より広範な環境に対応するモデルへの拡張も容易です。機械学習ポテンシャルの活用は、計算材料科学における解析の幅を大きく広げるものと期待されます。
本解析の詳細や、研究への適用に関するご相談はこちら
お問い合わせ参考文献#
- I. Batatia, D. P. Kovacs, G. Simm, C. Ortner, and G. Csanyi, "MACE: Higher Order Equivariant Message Passing Neural Networks for Fast and Accurate Force Fields", Adv. Neural Inf. Process. Syst. (2022).
- I. Batatia, et al., "A foundation model for atomistic materials chemistry", J. Chem. Phys. 163, 184110 (2025).
- A. van de Walle, M. Asta, and G. Ceder, "The alloy theoretic automated toolkit: A user guide," CALPHAD 26, 539 (2002).
関連ページ#
- 第一原理計算ソフトウェア Advance/PHASE
- 解析分野:ナノ・バイオ
- 産業分野:材料・化学