CHGNetのGPUによる高速化のベンチマーク#
ナノ材料統合GUI Advance/NanoLaboにおいて利用可能な汎用グラフニューラルネットワーク力場であるCHGNet1を用いた分子動力学計算について、GPUによる高速化のベンチマークを実施しました。 本事例では、硫化物リチウムイオン伝導体Li10GeP2S12を対象にベンチマーク計算を実施し、CPUのみを用いた場合との比較も行いました。
計算機環境#
本事例で使用した計算機のスペックを以下に示します。
- CPU:AMD EPYC 9554 (64 cores)
- GPU:NVIDIA H100
- CUDA:12.2
計算機環境の用意・使用にあたっては、HPCシステムズ様にご協力いただきました。
分子動力学計算の計算条件#
本事例では、Materials Projectより取得したLi10GeP2S12の構造ファイル (mp-696128) をもとに、スケーリングを変えながらスーパーセルモデルを作成し、CHGNetに実装されているMolecularDynamicsクラスを用いて分子動力学計算を実行しました。 分子動力学計算はNVTアンサンブル (T = 500 K) のもとで100ステップ行い、時間刻み幅は0.5 fsとしました。
CPUとGPUの比較#
CPU、GPUのそれぞれを用いて分子動力学計算を実行し、計算時間 t を計測しました。その結果を表および図に示します。表には、CPUとGPUの計算時間の比も併せて示しました。なお、いずれの場合においてもスレッド数は1として計算を行いました。
表からは、GPUはCPUの約7~8倍程度の速度で計算を実行できることがわかります。ただし、50原子系においてはCPUに対するGPUの計算速度は約3.54倍にとどまっており、系のサイズが小さい場合にはGPUの性能を十分に発揮することができないと考えられます。
| tCPU × 1 (sec) | tGPU × 1 (sec) | tCPU × 1/tGPU × 1 | |
|---|---|---|---|
| 50原子 | 11.52 | 3.25 | 3.54 |
| 400原子 | 70.80 | 8.39 | 8.44 |
| 1,350原子 | 244.76 | 31.15 | 7.86 |
| 3,200原子 | 615.96 | 85.76 | 7.18 |
| 6,250原子 | - | 172.25 | - |
| 10,800原子 | - | 293.91 | - |
| 12,600原子 | - | 349.90 | - |
| 13,500原子 | - | 367.34 | - |
図からは、CPU、GPUのいずれの場合も、原子数に対して計算時間がほとんど線形に増大していることがわかります。このことから、CPUに関して計算時間を計測していない3,200原子系より原子数の多い系についても、GPUはCPUに対して7~8倍程度の高速化を実現できていると推測できます。ただし、本事例で使用した計算機環境では14,700原子系の計算を実行した際にメモリ不足となり計算が停止しました。
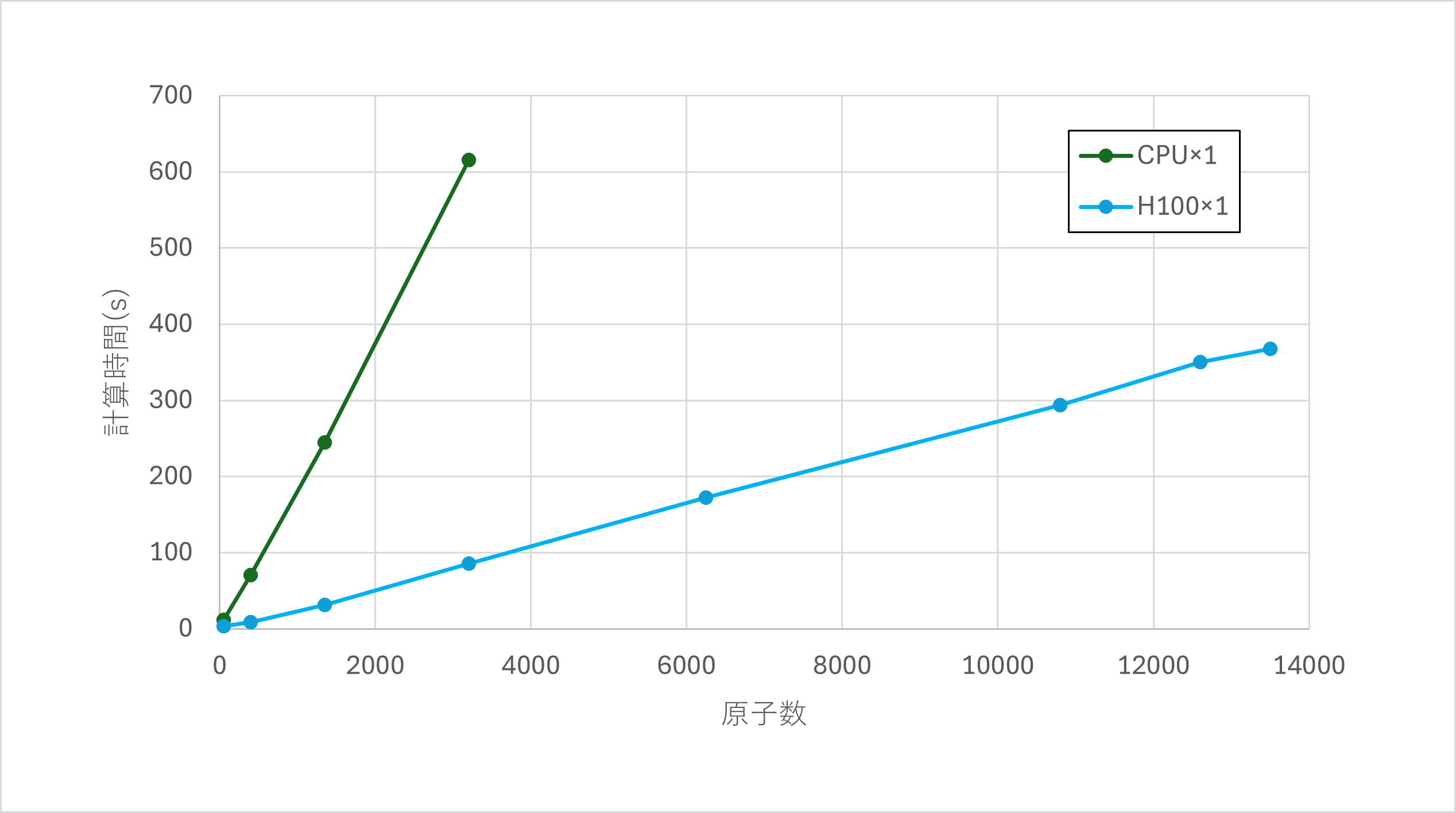
今回のベンチマークでは、GPUを用いることで、CHGNetによる分子動力学計算をCPUを用いた場合に比べて約7~8倍程度高速に実行できることがわかりました。弊社製品であるナノ材料統合GUI Advance/NanoLaboにおいても、CHGNetによる分子動力学計算でGPUを利用することができ、より短い時間でCHGNetによる分子動力学計算を実行して頂くことが可能となっています。
関連ページ#
-
Deng, B., Zhong, P., Jun, K. et al. CHGNet as a pretrained universal neural network potential for charge-informed atomistic modelling. Nat Mach Intell 5, 1031–1041 (2023). ↩